Read S3 object as byte array
Reads the contents of an Amazon S3 object into memory as a byte array. You can compare this to downloading a file. Prefer using streaming over reading as byte array if possible. Streaming is generally faster and uses less memory, because streaming doesn't require loading the entire object into memory before you can start working with the data.
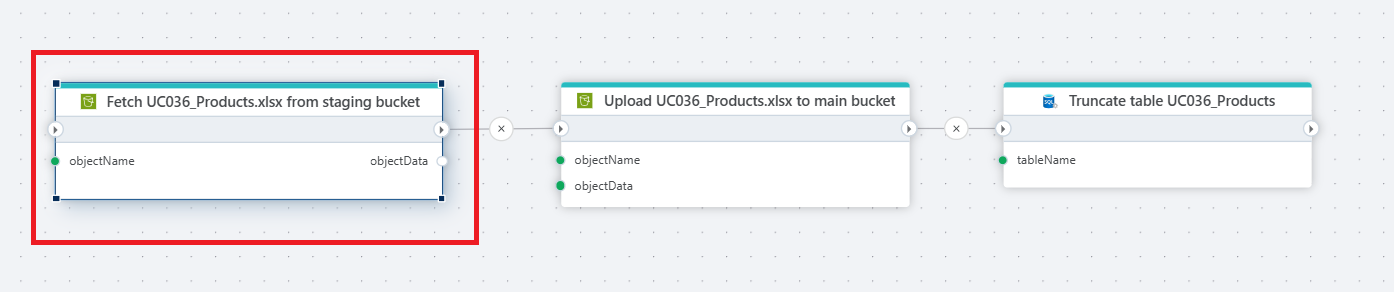
Example 
This flow ensures that the object is moved from a staging area to the main storage and then the corresponding table is cleared.
Note
If you need to read the file multiple times, for example processing its contents and then sending the file somewhere else (such as to an archive), you MUST use the byte array option instead of streaming because the stream can only read once.
Once you have the object contents, you must load it using a compatible action in order to make use of the data.
For example, an Excel file can be loaded using the Open Excel file as DataReader, Read Excel file as DataTable, or For each row in file actions. Once loaded, you can start working with the data in the Excel file.
Caution
Trying to load a byte array using an incompatible action will fail.
Properties
| Name | Required | Description |
|---|---|---|
| Title | No | The title of the action. |
| Connection | Yes | Specify the connection to the Amazon S3 bucket. |
| Object name | Yes | The name of the object to read from. |
| Result variable name | Yes | The name of the Flow variable that contains the list of the object names. |
| Description | No | Additional notes or comments about the action or configuration. |