Ranked Input
What is Ranked Input
Ranked Input enables providing input relative to different levels of dimensions. When data is saved, the Setting is "compiled" by unwrapping the data at the lowest level of the dimension based on the Ranked Input data.
If there is more than one column set up as a Ranked Input column, the result of the compilation will be the Cartesian product of the values at the lowest level of the dimensions.
Compile on Save
Enable this option to automatically compile the setting table when data is saved.
Note
that the compilation process can take some time, so if you do not need the compilation to run immediately, you can compile the setting at some later point using a Data Flow.
Automatically recompile when Ranked Input Column Source is updated
Enabled by default.
Requires that the solution model is compiled.
The contents generated when a Ranked Input Setting table is compiled is tied directly to the data and structure of the Ranked Input source dimension (hierarchy + levels).
That's why the Setting table needs to be recompiled whenever a Ranked Input source dimension is updated.
When this feature is enabled, InVision will automatically recompile the table when the Ranked Input source dimension is reloaded or updated.
This feature is enabled by default. Consider turning it off for setting tables where you have multiple Ranked Input Columns and it takes a long time to compile the output. The auto compilation will occur when a source dimension is updated, so a setting table with two Ranked Input Columns will be compiled two times.
If you are updating both dimensions, it is faster to disable this feature and compile the setting using in a custom Data Flow instead. This way, the compilation will only happen once, regardless of how many Ranked Input Columns there are.
Specificity
The Ranked Input data set is compiled based on specificity, where the order of the rows determines the specificity from lower to higher (think of it as a reversed rank).
When compiled, the result of the first (topmost) row is resolved first since it has the lowest specificity. Next, the result of each consecutive row is merged into the data set.
When the compilation of consecutive rows produces data matching rows already present in the data set, the existing rows are overwritten by the new ones.
For example, suppose you want to enter values relative to a Department dimension, you would put the Enterprise level setting as row 1, then any Region level setting(s) for overriding the Enterprise setting, and finally Department level settings as the final override.
To enable the user to order the rows in the desired order from lowest to highest specificity, you need to add a column to the Setting that the system can use for sorting the rows. The data type of the column must be Integer, but you are free to choose the name and index of the column.
Next, you need to specify that the column should be used for determining the specificity by going to the Features -> Ranked Input screen and choosing the column from the specificity Dropdown list.
When the specificity column has been set up, the user can move rows up and down using the context menu of the grid.
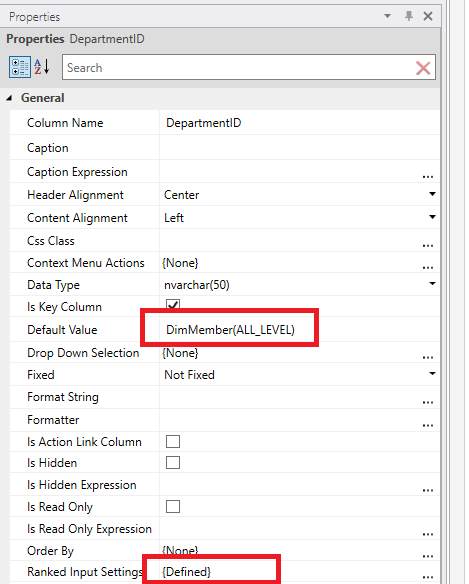
Default values
If you want cells in new rows in Ranked Input tables to get "All level" as default values, use DimMember(ALL_LEVEL) as the Default value of columns having the Ranked Input Settings property defined.