PdfTree
Namespace: Profitbase.Flow.Extensions.Adobe
Represents the structure of a PDF document returned from the Extract content from PDF as document tree action.
Implements
IEnumerable<PdfDocumentElement>
The PdfTree implements IEnumerable<T>, which means that you can query the PDF object structure using standard LINQ methods, like shown in the examples below.
Properties
| Name | Description |
|---|---|
| Document | The document root element of type PdfDocumentElement. |
Methods
| Name | Description |
|---|---|
| FindOrDefault(string id) | Returns the PdfDocumentElement with the specified id. |
| Contains(string id) | Returns true if the tree contains an element with the specified id, otherwise false. |
| Traverse(bool keepChildOrder = false) | Returns an IEnumerable<PdfDocumentElement> |
| ToJson() | Serializes the PdfTree as a JSON string. Useful for debugging purposes to explore how the PDF document is structured in a text editor. |
| System.Linq.Enumerable extension methods | Enables a wide range of APIs for searching, filtering or iterating over the elements in the document, for example the Where, Any, and FirstOrDefault methods. |
Example 1
This example shows how to extract the Total Amount from the sample invoice below.
We use the PdfTree API to get a reference to the document element with value Total Amount (this is the amount label), and then navigate from there to the element containing the actual value. In this case, the Total Amount value is in the table row just below the label itself. Keep in mind that all data is text, so if you need to perform math or other types numeric (or date) operations, you need to convert the values to correct data types first.
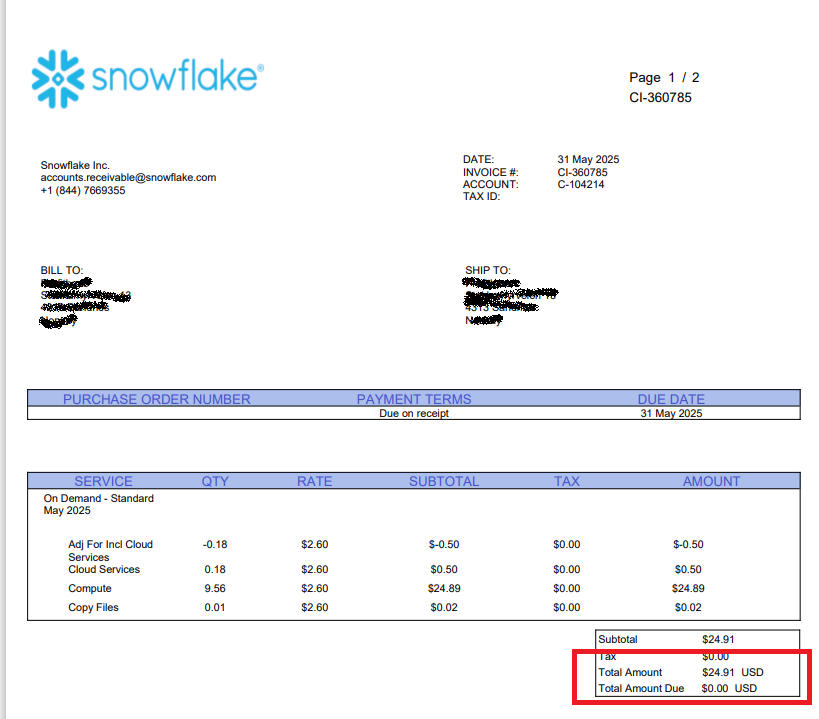
// PdfTree pdfTree = ...from an "Extract content from PDF as document tree" action
var totalAmountLabel = pdfTree.FirstOrDefault(element => element.Page == 0 && element.Value == "Total Amount");
if(totalAmountLabel is null)
{
return 0;
}
// Move up to the table row TD-> TR (Parent -> Parent), then access the second row of the TR (Children[1]) and then get the value of the object in the TD cell (Children[0].Value)
var totalAmountText = totalAmountLabel.Parent.Parent.Children[1].Children[0].Value;
// The amount is on the following format: $24.91 USD
var totalAmount = double.Parse(totalAmountText.Replace("USD", ""), NumberStyles.Currency, CultureInfo.CreateSpecificCulture("en-US"));
Example 2
This example shows how to extract the Compute SUBTOTAL from the sample invoice below.
It first finds the table containing the invoice lines, then finds the table row containing the "Compute" row header, and then
finds the 4th cell (.Children[3]) and picks the Value from cell object.
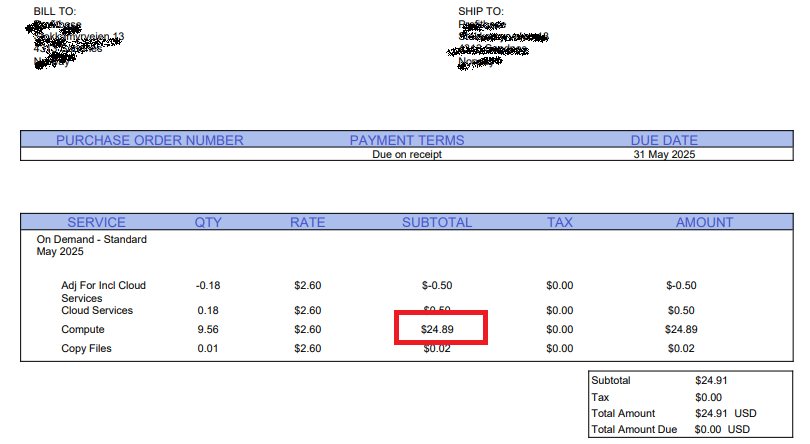
// PdfTree pdfTree = ...from an "Extract content from PDF as document tree" action
var serviceDetailsTable = pdfTree.Where(element => element.ElementType == "Table" && element.Descendants().Any(c => c.Value == "SERVICE")).FirstOrDefault();
// Locate the row containing the "Compute" row header.
var computeRow = serviceDetailsTable.Descendants().Where(c => c.Value == "Compute").First().Parent.Parent;
// Pick the value of the element in the 4th (Children[3]) cell (.Children[0]).
// Remember that the value is not stored in the cell itself, but rather in a nested child element of the cell.
var subtotalComputeText = computeRow.Children[3].Children[0].Value;
// The amount is on the following format: $24.89
var subtotalCompute = double.Parse(subtotalComputeText, NumberStyles.Currency, CultureInfo.CreateSpecificCulture("en-US"));