Extract content from PDF as document tree
Extracts content from a PDF file and returns it as a tree of elements.
Use this action if you need to query the contents of a PDF document in a structured way to extract information, such as invoice details or product information.
The action returns a PdfTree that you can use in a Function action to programatically read the contents of the PDF document.
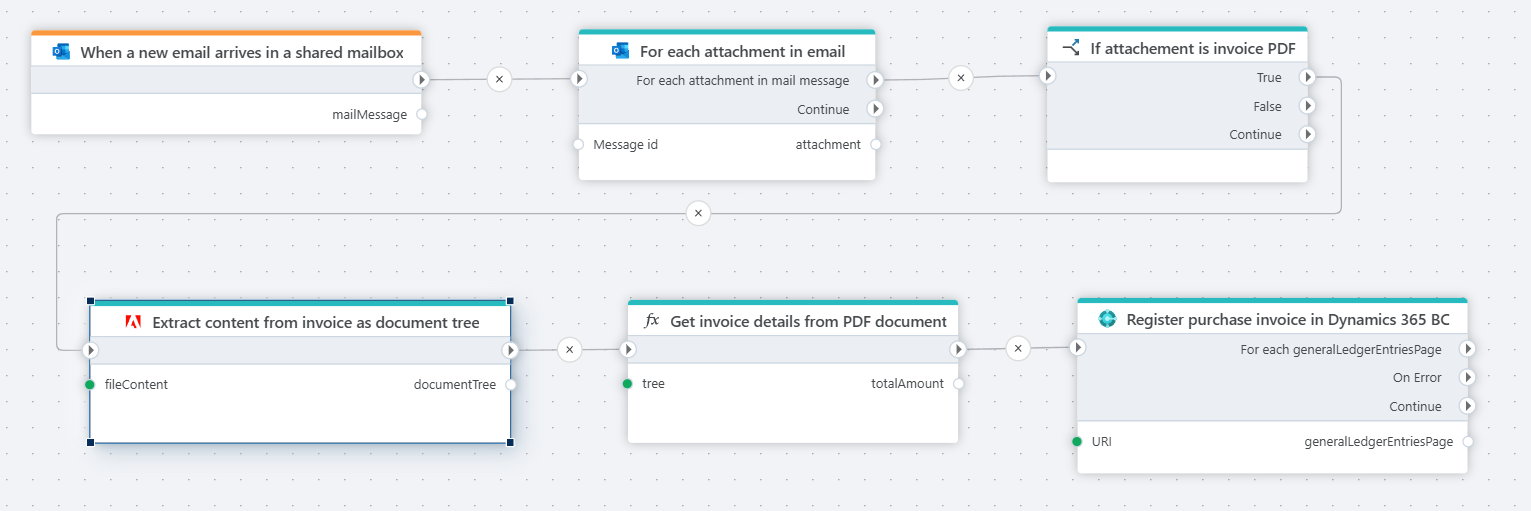
Example 
The example above shows a Flow that automatically processes incoming emails with invoice attachments, extracts the invoice details, and registers them in Dynamics 365 Business Central.
Properties
| Name | Type | Description |
|---|---|---|
| Connection | Yes | The connection for your Adobe PDF Services account. |
| File contents | Yes | A stream or byte array containing the PDF file contents. |
| Result variable name | Yes | The name of the variable containing the PdfTree that you can use in a Function to extract the information you want from the PDF document. |
Returns
This action returns a PdfTree that you can use in a Function to extract the information you want from the PDF document.
Example - Extract the Total amount from an invoice
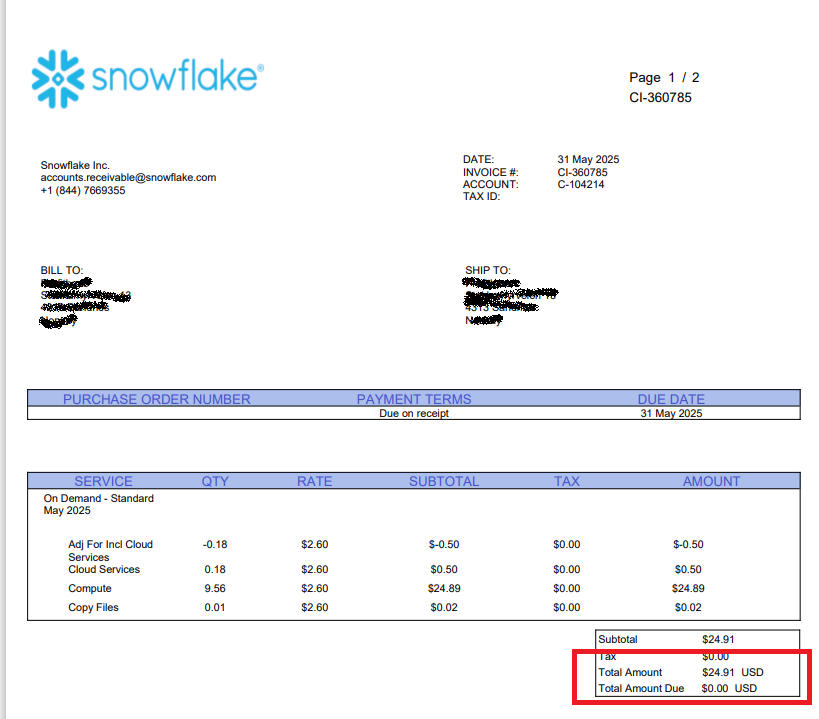
This example shows how to extract the Total Amount from the sample invoice below.
The invoice PDF file is passed in to the Extract content from PDF as document tree action, which returns a PdfTree which is passed to a Function as the pdfTree parameter.
We use the PdfTree API to get a reference to the document element with value Total Amount, and then navigate from there to the element containing the value. In this case, the Total Amount value is in the table row just below the label itself.
// PdfTree pdfTree = ...from an "Extract content from PDF as document tree" action
var totalAmountLabel = pdfTree.FirstOrDefault(element => element.Page == 0 && element.Value == "Total Amount");
if(totalAmountLabel is null)
{
return 0;
}
// Move up to the table row TD-> TR (Parent -> Parent), then access the second row of the TR (Children[1]) and then get the value of the object in the TD cell (Children[0].Value)
var totalAmountText = totalAmountLabel.Parent.Parent.Children[1].Children[0].Value;
// The amount is on the following format: $24.91 USD
var totalAmount = double.Parse(totalAmountText.Replace("USD", ""), NumberStyles.Currency, CultureInfo.CreateSpecificCulture("en-US"));
Example 2
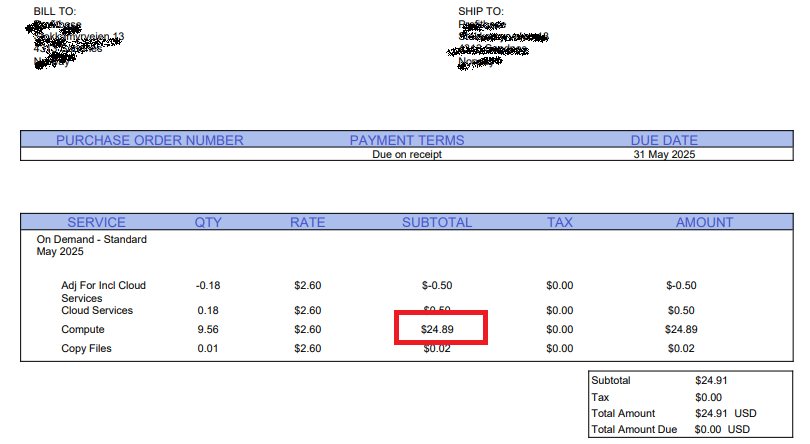
This example shows how to extract the Compute SUBTOTAL from the sample invoice below.
It first finds the table containing the invoice lines, then finds the table row containing the "Compute" row header, and then
finds the 4th cell (.Children[3]) and picks the Value from cell object.
// PdfTree pdfTree = ...from an "Extract content from PDF as document tree" action
var serviceDetailsTable = pdfTree.Where(element => element.ElementType == "Table" && element.Descendants().Any(c => c.Value == "SERVICE")).FirstOrDefault();
// Locate the row containing the "Compute" row header.
var computeRow = serviceDetailsTable.Descendants().Where(c => c.Value == "Compute").First().Parent.Parent;
// Pick the value of the element in the 4th (Children[3]) cell (.Children[0]).
// Remember that the value is not stored in the cell itself, but rather in a nested child element of the cell.
var subtotalComputeText = computeRow.Children[3].Children[0].Value;
// The amount is on the following format: $24.89
var subtotalCompute = double.Parse(subtotalComputeText, NumberStyles.Currency, CultureInfo.CreateSpecificCulture("en-US"));
Adobe PDF Services: Videos / Getting started
Generate a PDF file with tabular data
This video shows how to generate a PDF file with tabular data using the Adobe PDF Services API, and download the generated file from an InVision Workbook.