Tools AI Agent
Defines an AI Agent that can use tools to perform actions, for example fetching data or calling APIs.
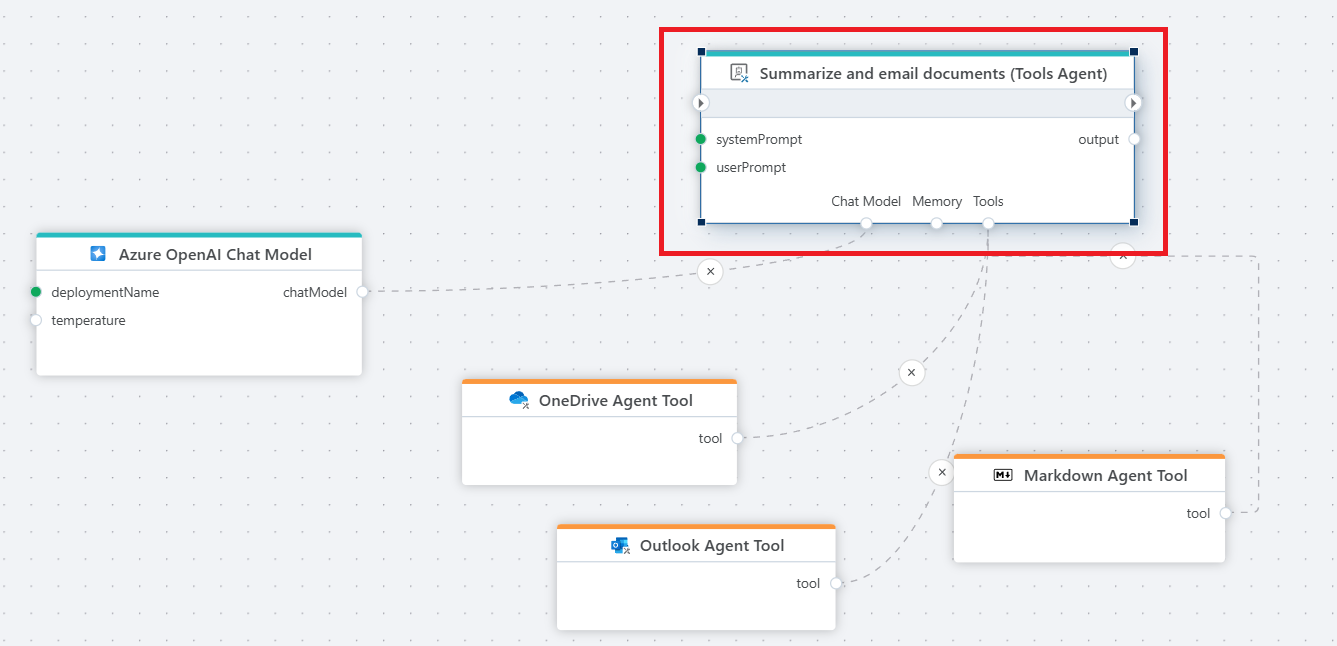
Example 
The example above shows an agent that reads all Word documents in a OneDrive folder, summarizes them, and emails the summaries along with the original documents as attachments. The following prompts are used:
Instructions
You are an agent that will use the tools provided to you to perform the tasks requested by the user.
If you cannot perform the task, stop without any retries.
User prompt
From OneDrive, get all Word (.docx) documents in the 'Work' folder.
For each document, get the file and create a summary.
Send an email from luke.skywalker@rebellion.com to darth.vader@empire.com that contains all the summaries.
Use the subject: 'Summary'.
Include all the Word documents as attachments to the email.
Properties
| Name | Required | Description |
|---|---|---|
| Tools usage | No | Specifies whether the agent should use tool calling directly, or write and execute code to use the tools. Read more about this topic below. |
| Instructions | Yes | The instruction given at the start of a conversation that sets the behavior, tone, and goals for the agent. It acts like a guide or personality primer, telling the chat model how it should respond (e.g., formal vs. casual), what role it should play (e.g., teacher, assistant, coder) and optionally what stategy you want it to prefer for decision making. |
| User prompt | Yes | This is the actual task that the agent is given, for example "Summarize all Word documents in my OneDrive folder named 'Work', and send the summarization to my-email@corp.com." |
| Session ID | No | A session ID is required if you want to enable memory, allowing for an ongoing conversation with the AI, rather than every interaction starting fresh. |
| Output mode | No | Agent response or Tool result. Specifies whether the output from the agent should be the (last) LLM response, or the raw output of the (last) tool call. Read more about agent output mode below. |
| Result data type | No | Specifies whether you want the output of the of the agent to automatically be converted to a stronly typed object, such as a "Customer" business object or list of business objects. By default, the agent outputs text, but this option enables conversion to data objects if the agent is properly configured for that purpose. Read more below. |
| Chat model | Yes | The chat model accepts a set of instructions, reasons about how to solve the task and utilizes tools to achive the final outcome. |
| Tools | Yes | One or more tools that the agent to use to perform the tasks identified by the chat model. Tools the agent can use includes: Azure Blob Storage Agent Tool OneDrive Agent Tool Outlook Agent Tool Markdown Agent Tool MCP client tool Flow AI tool |
| Memory | No | Agent memory used to store and retrieve a previous conversation with the agent. Allows for an ongoing conversation with the AI, rather than every interaction starting fresh. Note that memory requires a Session ID. |
Choosing a chat model
When choosing a chat model, it is important to choose a chat model that is capable of using tools. Not all chat models can use tools, and there's currently no official list of which chat models supports tool calling. You simply have to read the documentation for each LLM to determine whether tool / function calling is supported. A list of known LLMs with tool/function calling capabilities includes (but not limited to):
- OpenAI models: gpt
- Mistral AI models
- Anthropic models: Claude Sonnet, Claude Opus
- Meta Llama models
- Google Gemini models
If you enable Code mode in the Tools usage property, note that not all AI models are capable of reliably using this mode. In general, only the advanced models like GPT 5.2 or higher, Claude Opus and Sonnt 4.5 or higher produce reliable results in this mode. Smaller models like the GPT 5 mini series, DeepSeek, Kimi2 Thinking etc, are not capable of using code mode. Note that this may change in the future, so you'll just have to try out different models to see what works.
Choosing Tools
When building AI agents, it's best practice to keep their area of responsibility as narrow as possible. While this may seem counterintuitive to the concept of agents, giving an agent too many tools to choose from can negatively affect its accuracy when making decisions and selecting tools. It also increases token usage, and consequently, cost.
Tools usage
You can choose between two modes for how the agent can use tools: Tool calling or Code mode.
The mode you should choose depends on the complexity of the task, cost considerations, and the amount of data involved.
Both options are discussed below.
Note
If you enable Code mode in the Tools usage property, be aware that not all AI models can use this mode reliably. In general, only more advanced models—such as GPT 5.2 or later, Claude Opus, and Sonnet 4.5 or later—produce consistent results.
Smaller models, including the GPT 5 mini series, DeepSeek, and Kimi2 Thinking, currently do not support Code mode reliably. This may change over time, so it is recommended to test different models to see what works in practice.
Tool calling
In this mode, the AI agent uses traditional tool calling, where each tool is described to the LLM using a JSON schema. When the LLM reasons about what to do, it evaluates the available tools, selects the ones it needs, and calls them in sequence.
If multiple tools are required to complete a task, they are invoked independently, one by one. When a tool returns data, the result is added to the context and included in all subsequent requests to the LLM. Depending on the number of tools and the amount of data returned, this can have a noticeable impact on cost and performance, as the LLM must process the full context on every request.
Pros:
- Smaller and cheaper models (such as GPT mini or DeepSeek) can be used for simpler tasks, reducing cost.
Cons:
- The number of tools an agent can reliably use is limited. A common rule of thumb is to keep the total below 20.
- Data returned from tools is added to the LLM context and sent with every subsequent request, which can significantly increase token usage and cost.
- Tool definitions are included in every request, even when most tools are not used, leading to unnecessary token consumption.
Code mode
In this mode, the agent reasons about the task and inspects the APIs available through its tools to determine whether it can solve the task by writing and executing code.
Instead of calling each tool individually, the agent generates a single piece of code that uses all required tools and then executes it. For complex, multi-step tasks, this means the agent only needs to discover the APIs, write the code, and run it — typically requiring only two or three calls rather than one per tool.
Because the code is executed in isolation, data returned from intermediary tool calls is not added to the context. This significantly reduces token usage in scenarios where large amounts of intermediate data would otherwise be passed between steps.
Pros:
- More predictable behavior when working with a large number of tools
- For complex, multi-step tasks that require passing data between tools, code mode generally performs better and consumes considerably fewer tokens
Cons:
- Only large models with strong reasoning and coding capabilities can be used in code mode
When to use Tool calling vs Code mode
There is no strict boundary between when tool calling or code mode is the better choice. However, the following guidelines can help:
Use tool calling when:
- Only a small number of tools are available to the agent
- The tools do not pass large amounts of data between them (for example files, images, or data sets)
- The task does not require many tool calls
Use code mode when:
- A large number of tools are available, typically in more complex workflows
- The tools (may) need to exchange large amounts of data to reach the goal — for example when fetching and analysing the contents of files, images, or large data sets
Output mode
Options: Agent response or Tool result.
An agent can answer a question, perform a task that produces data, or perform a task without returning anything at all.
When you create an agent that returns data to Flow for further use, there are two ways to retrieve that data: from the last tool call or from the last LLM message.
Retrieving data from the last tool call gives you the raw output produced by the tool, such as a list of customers or email addresses.
Retrieving data from the last LLM message (Agent response which is the default) returns whatever the LLM chooses to produce after considering its tool calls, inputs, reasoning, and instructions.
If an agent is expected to return data in a specific, structured format—for example, a list of customer business objects—you should use the Tool result option, as it provides predictable output.
If an agent needs to analyze or reason about tool outputs before returning a response, you must use the Agent response option.
Result data type
The Result data type specifies the data type returned by the action. This makes the agent’s output easier to consume in subsequent actions in the flow.
The default is Object, which means no conversion is performed and the action returns whatever the agent produces (depending on the selected Output mode).
The selected data type must be compatible with the response from the underlying API. For example, if the LLM or a tool call returns a JSON string and you want the action to output a strongly typed business object or value, the structure of that object must match the JSON format. Likewise, if the model or tool returns a date string and Result data type is set to an integer, the conversion will fail due to incompatible types.
Memory
To enable ongoing conversations with the AI instead of starting fresh each time, you need to add memory to the agent. This allows it to recall previous exchanges when processing new requests. By remembering key details—like user preferences, goals, or past actions—the agent can personalize responses, avoid repetition, and maintain continuity. The result is more natural, efficient, and human-like interactions, where the AI can reason and adapt over time.
Flow has multiple built-in memory provides, such as Agent memory for SQL Server
Note
To use memory, you need to specify a Session ID. The Session ID is usually provided by the client, because the user (client) decides when they want to start a new conversation.
Best practice when using memory
- Use separate memory storage for each agent. For example, when using SQL Server for agent memory, store each agent’s memory in its own table.
- Apply a memory or chat reducer, such as the Chat history truncation reducer, to limit the size of the conversation history sent with each request. Because LLMs are stateless and receive the entire conversation history every time, token usage and costs increase, accuracy tends to decrease, and responses take longer. A reducer automatically trims the conversation history to keep it at a manageable level.