Streaming chat completion
This action defines a Microsoft Foundry streaming chat completion model that processes a prompt and delivers the response in small pieces as it is generated. Using a streaming chat completion improves responsiveness and gives the user real-time insight into the model’s output as it forms.
It's typically used when building backends for interactive chat clients, assistant-like experiences, or any UI that needs incremental model output.
Unlike the standard chat completion, this action returns the response incrementally as it is generated.
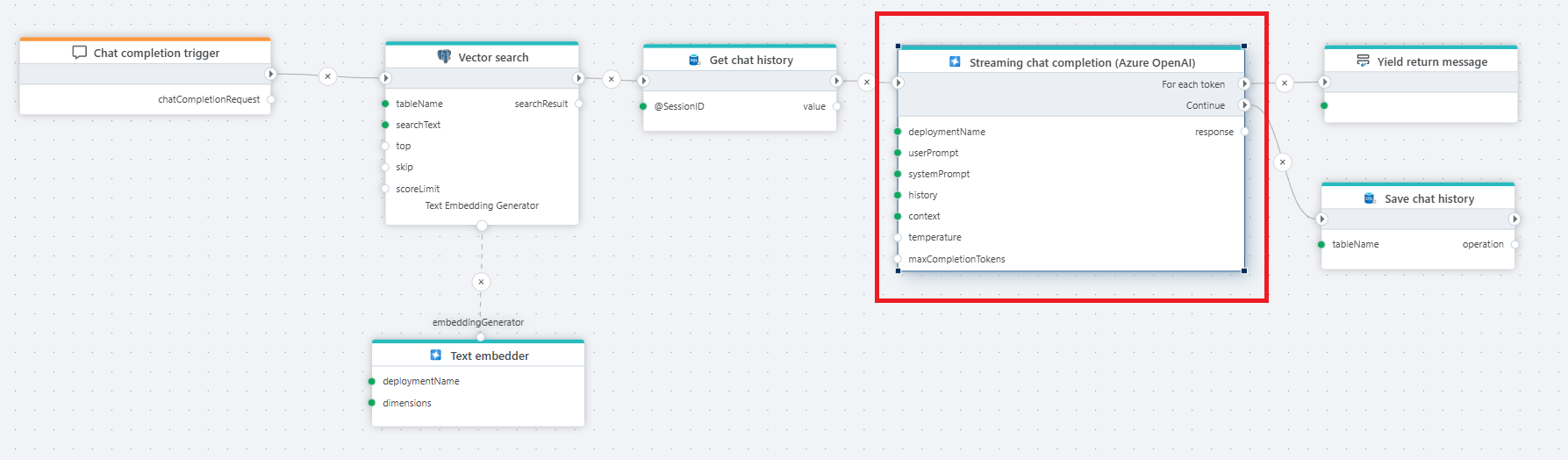
Example 
The example above shows a Flow that provides chat completions to a chat client. We're using PostgreSQL vector search to enable RAG, and SQL Server to store and retrieve the chat history so that users can ask follow-up questions.
Properties
| Name | Required | Description |
|---|---|---|
| Title | No | The title of the action. |
| Connection | Yes | Defines the connection to an Microsoft Foundry resource. |
| Enable dynamic connection | No | A Dynamic Connection will override the connection on flow execution. |
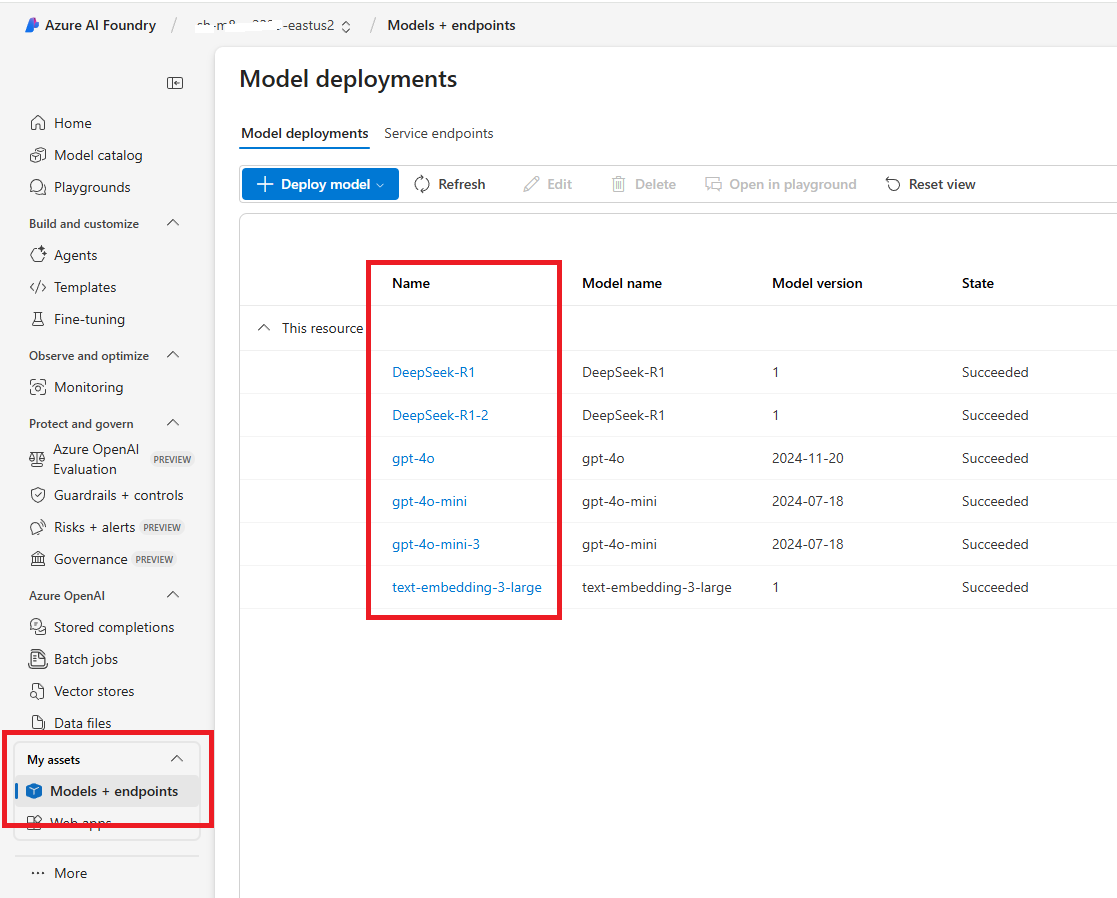
| Model | Yes | Specifies the model deployment name, which corresponds to the Name (not the model id) of the deployed model in Microsoft Foundry (see below). In the Azure Portal, the deployment name can be found under Resource Management > Model Deployments. |
| User Prompt | Yes | The input message from the user, which the model processes to generate a response. |
| System Prompt | No | A system-level instruction that guides the model’s behavior and response style. |
| History | No | A record of past interactions that provides context to the conversation, helping the model maintain continuity. |
| Context | No | Typically used for RAG, and provides additional information or domain-specific knowledge to the chat model so it can make more accurate responses. The input can be a string (text) or a vector search result, such as the result from the PostgreSQL Vector Search action. |
| Prompt template | No | Defines the structure of the prompt sent to the model. The system replaces the placeholders @@context and @@userPrompt with the relevant information. See example below. |
| Temperature | No | Temperature in models controls the randomness and creativity of the generated responses. Lower temperatures (e.g., 0.2) produce more focused, predictable text, ideal for tasks that require precision. Higher temperatures (e.g., 1.5) increase creativity and variability, but may risk generating less coherent or relevant content, making it important to adjust based on your desired outcome. The default is 0.7 if nothing is defined by the user. |
| Max Completion Tokens | No | Sets a limit on the number of tokens (words, characters, or pieces of text) in the model’s response. |
| Result Variable Name | No | Stores the generated AI response. Default: "response". |
| Enable Grounding | No | Enables grounding to improve factual accuracy using external or structured context. |
| Disabled | No | If enabled, the action is skipped during flow execution. |
| Description | No | Additional details or notes regarding the chat completion setup. |
Returns
This action emits a stream of AIChatCompletionResponse objects, where each event contains a partial model output, usage metadata (if available), and provider-specific data.
Models
To find the Model deployment name, look in Models screen in Microsoft Foundry.
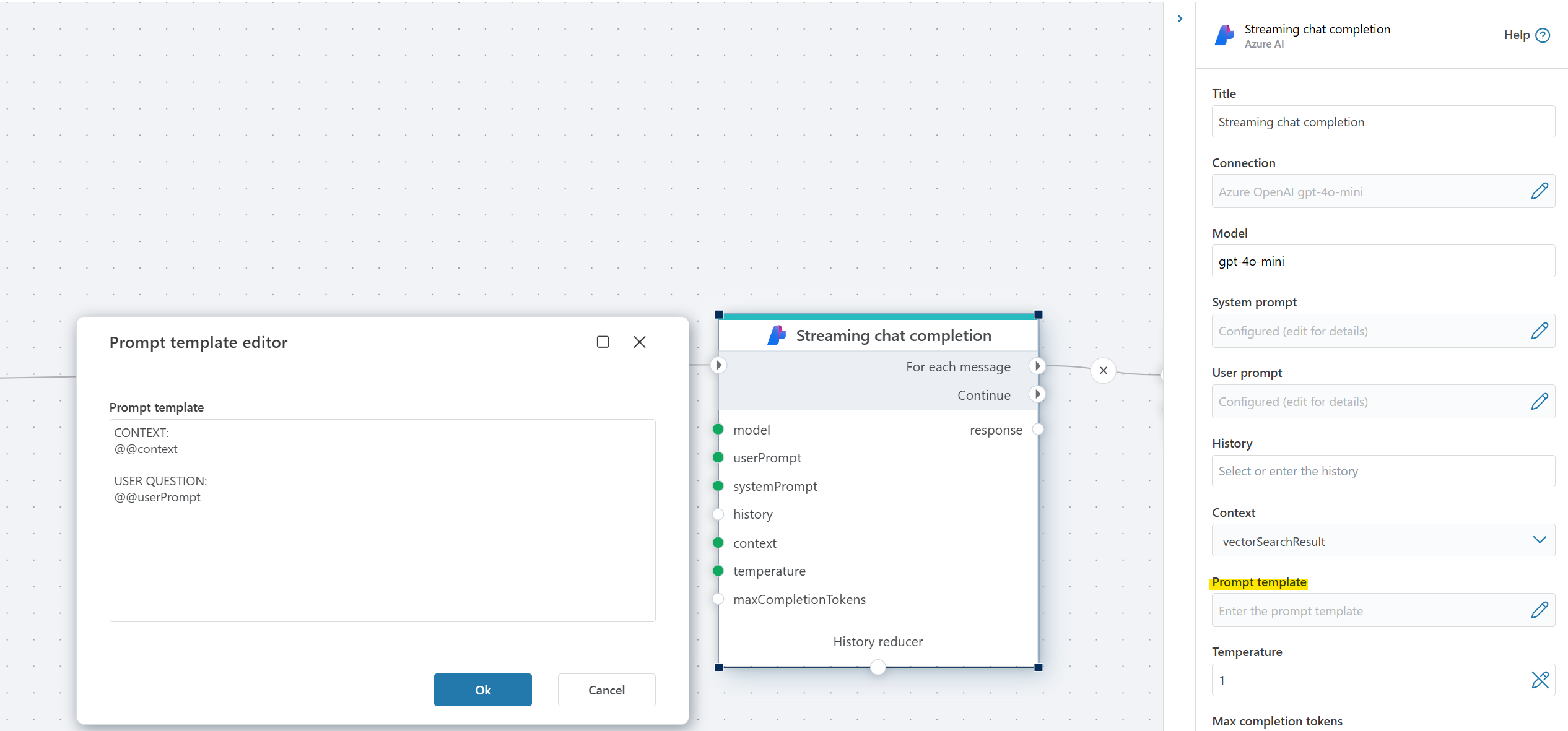
Prompt template
The prompt template allows you to specify the format of the prompt that is sent to the language model. This is useful for customizing how context and instructions are provided to the model. Within the template, you can use the following placeholders:
@@context: This is replaced by the "Context" property value.@@userPrompt: This is replaced by the "User prompt" property value.
The system will substitute these placeholders with the corresponding values before sending the prompt to the model.
Example 
Azure AI: Videos / Getting started
This section contains videos to help you get started quickly with Azure AI in your Flow automations.
Create an AI chat solution using InVision and Flow
This video shows how to build an AI chat solution using Hypergene InVision and Flow. It includes how to populate a vector database, and use the vector database in a RAG-based chat completion flow to answer user questions from PDF product sheets.