Read CSV file as DataTable
Loads the contents of a CSV file into memory as a DataTable.
This action is typically used when you need to import small to mid-sized CSV files to a database (< 250 000 rows). The DataTable can be used as input to actions such as the SQL Server Insert Data action.
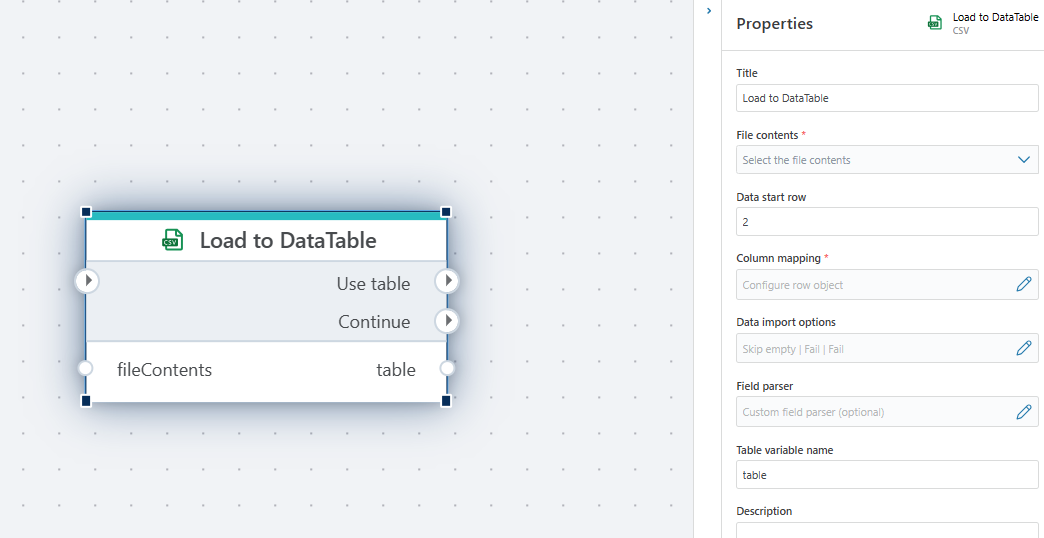
Properties
| Name | Type | Description |
|---|---|---|
| Title | No | A descriptive title for the action. |
| File contents | Yes | The contents of the file, provided as either a stream, byte array or string with valid CSV data. |
| Data start row | No | Specifies the index of the row where the data starts. If the file has a header row, the data start row is typically 2. If the files does not have a header row, the start row is usually 1. |
| Column mapping | No | The mapping between the field indices and field data types in the file, and the columns in the final data set. If you don't specify a column mapping, it is required that the first line in the file is a header record. Also, if you don't specify a column mapping, all fields will be read as string. |
| Data import options | No | Specifies options for error handling and how the contents of the file is parsed, such as dates and numbers. |
| Field parser | No | Provides advanced options to handle parsing of field values during the import. |
| DataReader variable name | Yes | The name of the variable you can use to reference the DataTable in other actions. |
| Description | No | Additional notes or comments that describe what the action does. |
Handling bad data
When importing data from a CSV format, you often get bad data in form of badly formatted values, missing fields, or simply unexpected values. In a large data set, bad values may constitute a small amount of data, making them hard to track down. By enabling Error handling behaviors in the Data import options, you can record the bad data encountered during a CSV import and investigate which rows and fields prevent a successful import.
Read about handling bad data here
Note
If you don't specify Column mappings, or specify the data type of all columns as string, all values in the file will be read as text (string). No data conversion or formatting will be performed, so you will simply get the raw data in the file. Note, however, that you should enable the Data import options to skip empty rows and / or missing fields in case the file itself is badly formatted. Optionally, you can use the Open CSV file as DataReader action instead, if you want to import empty fields when no column mappings are defined.
CSV: Videos / Getting started
This section contains videos to help you get started quickly working with CSV files using Flow.
Dump CSV file from Azure Blob container to Azure SQL table
This video demonstrates how to import all records from a CSV file into an Azure SQL table.
In the demo, no data import options (such as data type conversion, number or date formatting) are specified, meaning the data is imported as raw text.