Save vectors
Generates and saves vector records to a PostgreSQL database from text input.
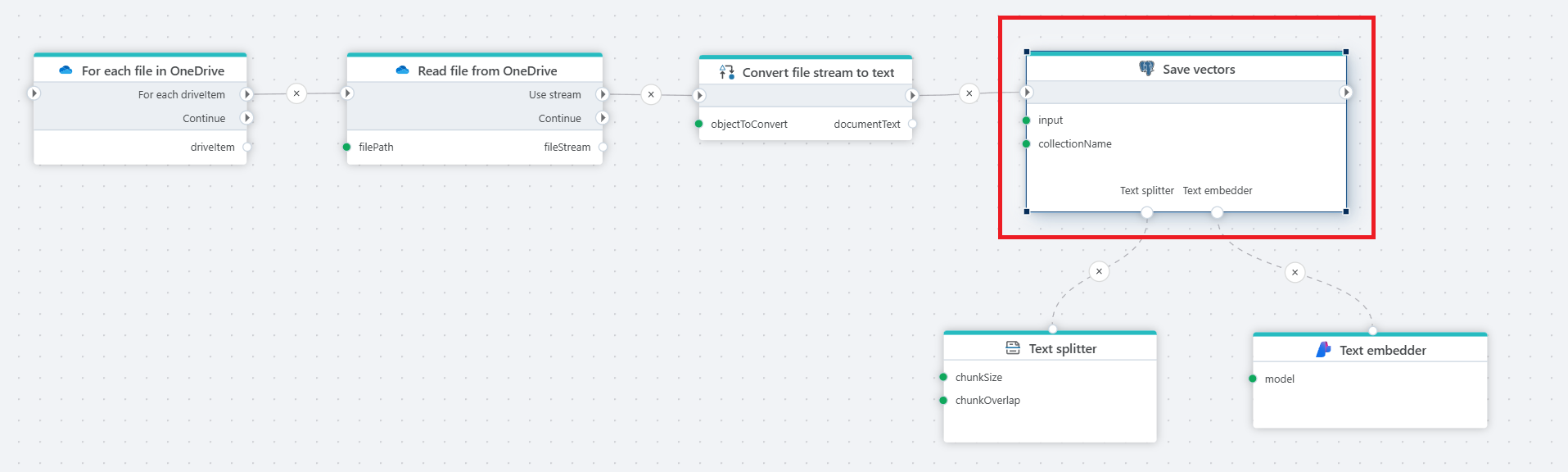
Example 
This flow reads files from OneDrive, converts their content to text, splits it into chunks, generates embedding vectors, and stores them in a PostgreSQL database for semantic search.
This action allows saving a text as a list of records in a PostgreSQL vector collection, in a specific format (Profitbase). This is done using the following steps:
- Split - The input text is split into chunks using the Text splitter (link).
- Embed - Each of the chunks resulting from the previous step is embedded using the Text embedder (link)
- Build - A new collection record is built for each of the embedded chunk.
- Upsert - The newly created record is inserted in the database collection.
Properties
| Name | Required | Description |
|---|---|---|
| Title | No | The title or name of the action. |
| Connection | Yes | Select or define your PostgreSQL connection. |
| Input text | Yes | Text to vectorize and save. Can be a variable or static string. |
| Collection name | Yes | The name of the table or collection in the database where vectors are saved. |
| Record definition | Yes | The definition of columns used in the vector search. Column names need to be alphanumeric and can contain underscore. Note: The vector column is not returned. |
| Command timeout (seconds) | No | The time limit for command execution before it times out. Default is 120 seconds. |
| Description | No | Additional notes or comments about the action or configuration. |
Collection Schema
The collection has the following columns. Column names must be alphanumeric and may contain underscores.
| Name | Type | Datatype | Description |
|---|---|---|---|
| Key | Required | String | Contains the record's key. This is automatically generated by the node. |
| Content | Required | String | Contains the plain-text of a chunk. |
| Vector | Required | String | Contains the vector representation of the content column. |
| Context | Optional | String | Defines the context associated with the text entered in the node (e.g., document name, URL, or resource ID). This context acts as a unique identifier and is used to delete any existing data with the same context before inserting the new data into the collection. |
| Custom | Optional | String | For each custom column defined in the node, a new collection column will be created (including the specified data type). |
Note
In order to use this action, make sure that your Postgres instance has the pgvector extension installed.