Data integration and transformation
Hypergene Flow offers extensive support for connectors and data adapters across various systems, including databases, ERP systems, email, collaboration tools, cloud storage, files and many more
As data is updated in disparate systems by users or applications, Hypergene Flow can pick up these changes and automatically take action to synchronize the data or apply changes to other systems. This makes data flow seamlessly between systems without manual user intervention.
Flows that support this process typically does the following:
- Connects to, and reads data from one or more source systems through APIs such as HTTP (REST), databases, mail, and messaging services like Teams, Azure Service Bus and RabbitMQ.
- Applies business logic to the data as a series of transformations, calculations, filtering, enrichments, or validations.
- Connects to the target systems and applies changes accordingly by adding, updating or deleting data.
- Optionally, notifies other services or users through tools such as Teams, Slack, mail or messaging services (Azure Service Bus, RabbitMQ, Apache Kafka, etc)

Example - Connect your ERP system and data platform for reporting
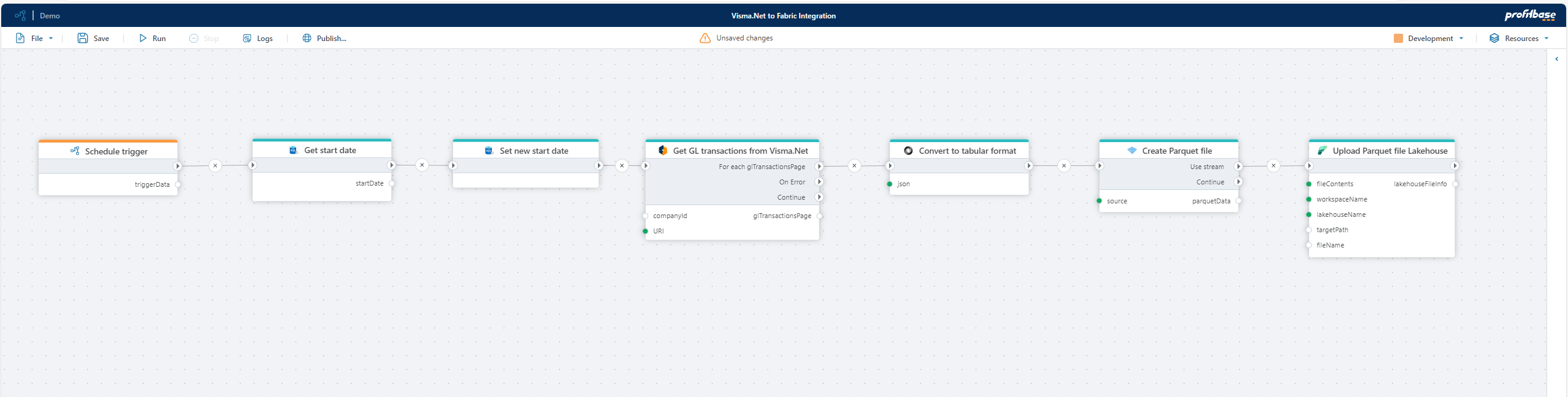
Here’s an example of setting up an integration between Visma.Net (ERP) and Microsoft Fabric using Hypergene Flow. We'll configure an automated process to continuously retrieve the latest general ledger transactions and upload them to Microsoft Fabric for reporting in Power BI. The entire configuration can be set up with virtually no code.
The Flow does the following:
- Run on a schedule: The first step is to add a Schedule trigger to make the Flow run repeatedly on a schedule, for example nightly or hourly.
- Retrieve the last fetch time: To avoid reloading the entire general ledger every time, we first retrieve the last fetch date/time and record the current time for the next execution. In this example, we store this information in an Azure SQL database, but any supported storage option can be used.
- Fetch new transactions: Using the Visma.Net REST API and the paged REST APIs action, we fetch GL transactions newer than the last fetch date/time. The transactions are returned in JSON format as paginated chunks, which we upload to Microsoft Fabric one at a time.
- Convert JSON to Parquet: Since JSON is inefficient for tabular data, we use the JSON Data Reader and Create Parquet file as stream actions to convert the data into a format optimized for data analysis.
- Upload to Microsoft Fabric: Finally, the Parquet file is uploaded to Microsoft Fabric using the Upload to Lakehouse action. The data is now available for reporting and analysis in tools such as Power BI.